Modelle
- Seedance 2.0BeliebtNeu
- Veo 3.1 PremiumBeliebt
- GPT Image 2Neu
- Nano Banana 2Beliebt
- Seedream 5.0
- Kling 3.0
- Z-Image Turbo
- Grok Imagine Bild
Laden...
Laden...
Laden...
GPT Image 2 fühlt sich weniger wie ein schnelles Spielzeug für Bilder und mehr wie ein Modell für echte Produktionsarbeit an. Es ist besonders stark bei langem Text-Rendering, wissensintensiven Motiven, komplexen kommerziellen Layouts, präziser Kontrolle mehrerer Bildelemente und nahtlosen lokalen Bearbeitungen. Dadurch eignet es sich besonders gut für Poster, E-Commerce-Visuals, Weltkarten, medizinische Illustrationen, Produktanzeigen und hochwertige Publishing-Assets.
Zentrale Fähigkeiten von GPT Image 2
Nach dem aktuellen Modellprofil ist GPT Image 2 besonders stark bei nahezu perfektem Text-Rendering, weltwissensbasiertem Realismus, produktionsreifen 4K-Ausgaben, besserer Prompt-Treue und pixelgenauer Bearbeitung.
GPT Image 2 macht einen deutlichen Sprung bei textlastiger Bilderzeugung. Es rendert lange Phrasen, mehrteilige Labels und layoutkritische Texte wesentlich stabiler und stilistisch konsistenter. Auch Groß- und Kleinschreibung, Zeichensetzung und komplexe Typografie werden zuverlässiger verarbeitet. Das macht das Modell besonders nützlich für UI-Mockups, mehrsprachige Produktlabels, Filmplakate, Zeitungsseiten und Handelsgrafiken, bei denen der Text selbst direkt nutzbar sein muss.

GPT Image 2 scheint Weltwissen deutlich effektiver zu integrieren, was typische KI-Halluzinationen reduziert. In der Praxis ist es stärker bei medizinisch strukturierten Visuals, Weltkarten und erklärungsorientierten Bildern, die eher auf faktischer Struktur als auf reinem Stil beruhen. Das verschafft ihm Vorteile bei wissensintensiven Anwendungen in Bildung, Publishing und professioneller Kommunikation.
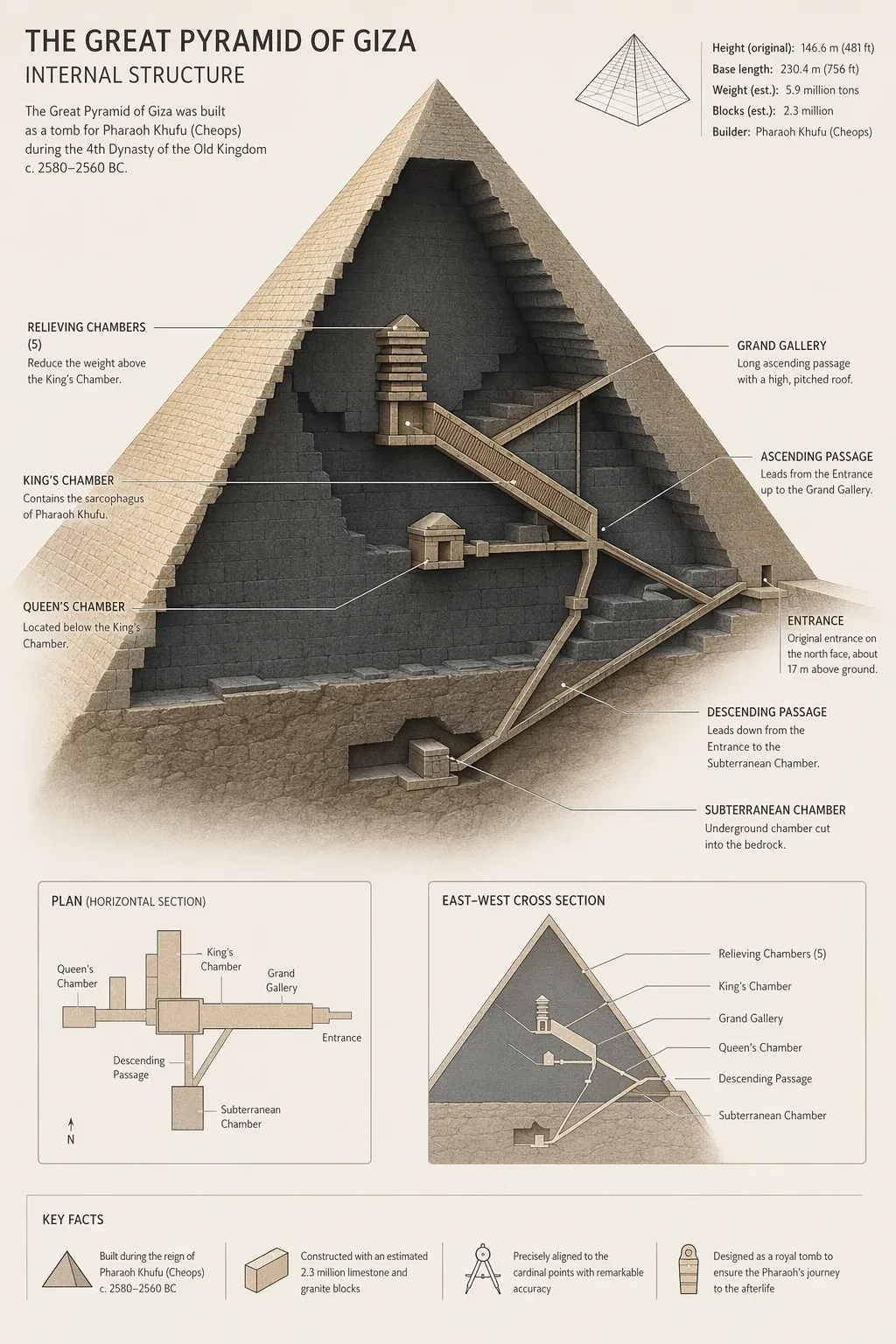
GPT Image 2 ist für professionelle Workflows konzipiert und unterstützt hochauflösende Ausgaben bis 4096×4096 sowie flexible Seitenverhältnisse. Das Modellprofil hebt außerdem extra-breite Kompositionen wie 3:1 hervor. Dadurch eignet es sich für detaillierte Produktanzeigen, großformatige Banner, digitale Publishing-Layouts und kommerzielle Assets, bei denen Auflösung eine entscheidende Rolle spielt.

GPT Image 2 versteht lange, vielschichtige Prompts deutlich besser. Du kannst visuelle Hierarchien, Farbsysteme, Kleidungsdetails und Beziehungen zwischen Objekten in einer einzigen Anfrage definieren, und das Modell hält diese Vorgaben meist zuverlässiger ein. Dadurch ist es besonders nützlich für E-Commerce-Layouts, Fashion-Kampagnen, kommerzielle Poster, Produktpräsentationen und Designaufgaben mit höherer struktureller Komplexität.

GPT Image 2 ermöglicht präzisere lokale Eingriffe. Wenn du Elemente hinzufügst oder änderst, fügt sich der neue Inhalt natürlicher in Licht, Schatten und das gesamte visuelle Umfeld ein, anstatt den Rest des Bildes zu zerstören. Dadurch eignet es sich besser für präzise Überarbeitungen bestehender Assets als für eine komplette Neuerzeugung bei jedem kleinen Änderungswunsch.

Der Ablauf ist einfach: Öffne den GPT Image 2-Workspace, beschreibe dein Ziel, passe die passenden Einstellungen für die Aufgabe an und generiere oder lade anschließend das Ergebnis herunter.
Starte direkt von der GPT Image 2-Seite auf AnyAIHub. Wenn du über den allgemeinen Bild-Workspace einsteigst, kannst du im Modell-Auswahlmenü auch zu GPT Image 2 wechseln und von dort weitermachen.
Schreibe einen klaren Prompt, der Motiv, Stil, Komposition, Licht, Text und Beziehungen zwischen den Elementen beschreibt. Wähle danach das passende Seitenverhältnis, den richtigen Referenzbild-Ansatz und weitere Einstellungen passend zum gewünschten Ergebnis.
Erzeuge das Bild und prüfe das Ergebnis nach wenigen Sekunden. Wenn es schon nah dran ist, aber noch nicht ganz passt, verfeinere den Prompt und starte erneut. Sobald das Ergebnis stimmt, lade das finale Asset herunter und überführe es in deinen Produktionsprozess.
GPT Image 2 passt besonders gut zu Teams und Creators, denen visuelle Wirkung allein nicht reicht. Wenn Textgenauigkeit, strukturelle Logik, Layout-Stabilität und hochauflösende Ergebnisse in deinem Workflow wichtig sind, ist dieses Modell deutlich näher an einem Produktionswerkzeug als an einer reinen Inspirationsmaschine.
Eine starke Wahl für Teams, die Social Creatives, Paid-Ads-Visuals, Kampagnenmotive, E-Commerce-Banner und markengetriebene Assets in größerem Umfang produzieren. GPT Image 2 ist besonders nützlich, wenn der Text im Bild nicht nur dekorativ sein darf, sondern tatsächlich verwendbar sein muss.
Nützlich für Interface-Mockups, Landingpage-Visuals, Verpackungskonzepte, gelabelte Produktbilder und mehrsprachige E-Commerce-Assets. Im Vergleich zu stilorientierten Bildmodellen ist GPT Image 2 besser für Aufgaben geeignet, die saubere Struktur, korrekte Informationen und klare räumliche Beziehungen brauchen.
Sehr gut geeignet für Lehrgrafiken, wissenschaftliche Diagramme, strukturierte Erklärbilder, Weltkarten und Inhalte mit faktenbasierter Einordnung. Sein stärkeres Verständnis für Weltwissen und logische Struktur macht es zu einer besseren Wahl für Teams, die sowohl Lesbarkeit als auch inhaltliche Genauigkeit brauchen.
Eine praktische Option für Buchcover, Editorial-Art, Magazinlayouts, Filmplakate und hochauflösende Konzeptvisuals. Wenn ein Projekt 4K-Ausgabe, komplexe Kompositionen, präzise Typografie oder genaue lokale Überarbeitungen erfordert, kommt GPT Image 2 einem produktionsreifen Ergebnis deutlich näher.
Diese Antworten decken die häufigsten Fragen rund um GPT Image 2 ab — darunter, was das Modell ist, warum es heraussticht, welche Bildarten es gut beherrscht und wie du auf AnyAIHub damit startest.
GPT Image 2 ist ein multimodales Bildmodell der nächsten Generation von OpenAI. Es verbessert Text-Rendering, hochauflösende Ausgabe, die Verarbeitung komplexer Anweisungen und dialogbasierte Bearbeitung auf Pixelebene — und ist damit eine deutlich stärkere Option für professionelle Bild-Workflows, die Präzision und Verwendbarkeit verlangen.
GPT Image 2 ist besonders hilfreich für produktionsnahe Workflows, die mehr als reine Ästhetik brauchen. Es ist besser beim Rendern von Labels, Buttons, Poster-Text und strukturierten Layout-Inhalten und zeigt zugleich ein stärkeres Verständnis für reale Details, visuelle Logik und Szenenkonsistenz. Dadurch eignet es sich besonders gut für UI-Mockups, kommerzielle Poster, E-Commerce-Verpackungen und wissenschaftliche oder erklärende Visuals.
Ja. AnyAIHub bietet neuen Nutzerinnen und Nutzern ein begrenztes Testkontingent, um Bildmodelle wie GPT Image 2 auszuprobieren. Nach der Registrierung kannst du direkt starten. Wenn du mehr Volumen, höhere Limits oder einen längerfristigen kommerziellen Workflow brauchst, musst du in der Regel upgraden oder zusätzliche Credits kaufen.
GPT Image 2 kann eine große Bandbreite an Ergebnissen erzeugen, darunter fotorealistische Szenen, historische Rekonstruktionen, Infografiken, moderne UI- und UX-Wireframes, E-Commerce-Verpackungsvisuals, markenorientierte Poster, gelabelte kommerzielle Grafiken sowie layoutgetriebene Visuals, bei denen sowohl Struktur als auch Lesbarkeit wichtig sind.
Nein. GPT Image 2 versteht natürliche Sprache gut, sodass du dein gewünschtes Ergebnis in ganz normaler Alltagssprache beschreiben kannst. Egal ob du von Grund auf generierst oder gezielte Änderungen an einem bestehenden Bild willst — klare Anweisungen reichen in der Regel aus, um starke Ergebnisse zu bekommen.
Ja, und genau das ist eine seiner größten Stärken. GPT Image 2 ist deutlich zuverlässiger bei mehrteiligen Labels, Posterüberschriften, Verpackungstext, Buttons und anderen layoutkritischen Textelementen. Dadurch werden viele der typischen Probleme anderer Bildmodelle reduziert — etwa unleserlicher Text, falsche Schreibweise oder verzerrte Layouts.
Wenn du mehr als nur schöne Bilder brauchst — also mehrsprachige Layout-Qualität, wissensbasierte Visuals, druckfähige 4K-Commercial-Assets und präzise lokale Bearbeitung — ist GPT Image 2 die deutlich stärkere Wahl für echte Produktionsarbeit.