加载中...
加载中...
加载中...
加载中...
Seedance 2.0 主打更强的结构控制与创意精度,可结合文本、图像、视频片段和音频作为参考来生成视频。它强调角色与物体的一致性、动作的真实物理表现,以及从创意复刻到前后向视频扩展的完整控制能力,适合希望把视频生成流程做得更专业的团队和创作者。
Seedance 2.0 的核心能力集中在多模态引用、真实动作、视觉一致性、创意复制、故事板理解和无缝视频扩展。
通过上传组合资产,例如角色图像、背景视频或音轨,Seedance 2.0 可以更精确地合成这些元素。它能理解参考素材中哪些细节需要保留,从灯光氛围到复杂角色动作,都能更准确地传递到输出视频里。

2.0 版本显著增强了动作与物理表现。从水流到头发运动,每一个动态细节都更稳定、流畅、逼真。即使没有复杂参考,仅凭基础文本到视频生成,也能得到更专业的动态表现。

AI 视频常见的问题是角色和细节在镜头间漂移。Seedance 2.0 通过锁定关键元素来解决这个问题,从产品标签到服装细节,都能在整段视频里保持更高一致性,减少闪烁和不必要的形变。

Seedance 2.0 可以模仿参考视频的节奏和结构,识别其中的摄像机语言、转场方式和视觉组织,让你无需复杂术语,也能复刻更专业的视频表达。

Seedance 2.0 对叙事和场景逻辑有更深的理解。它不只是生成单个片段,还能根据复杂的故事板和详细提示词组织镜头顺序,让输出更贴近完整叙事而不是零散片段。
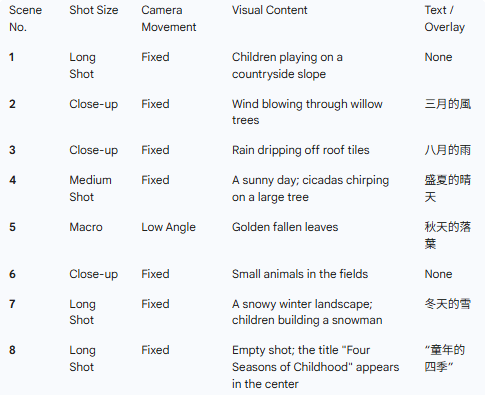
借助增强的视频扩展能力,Seedance 2.0 可以分析现有片段并生成自然延续。无论是向前补足铺垫,还是向后延长高潮之后的镜头,都能更好地保持环境与角色连续性。

从创意描述到参数配置,再到 AI 生成与最终导出,Seedance 2.0 提供一条更完整的视频生成工作流。
输入详细提示词,或上传参考图片到 Seedance 2.0。你可以描述角色、场景、摄影角度和动作,让模型理解更细致的导演级指令,从而实现更精确的场景构图。
选择适合的分辨率、宽高比和视频时长。Seedance 2.0 支持更灵活的输出控制,方便你按平台规格和创意目标调整最终生成结果。
让 Seedance 2.0 开始生成。模型会输出高保真视频帧,呈现更真实的运动效果、更连贯的多镜头序列,以及更完整的整体视频生成流程。
预览生成结果后,下载可直接使用的 MP4 文件。生成的视频可用于社交平台分发,也能继续进入你的专业视频制作流程。
以下问题与回答整理自 Seedance 2.0 页面内容,重点覆盖多模态参考、一致性、商业用途、视频编辑、物理表现和故事板理解等核心能力。
Seedance 2.0 的突出优势在于多模态参考能力。许多模型主要接受文本或单张图像,而它还可以读取视频和音频,并据此复制特定动作、节奏和风格,因此能提供更高程度的创意控制。
该模型通过更强的时空逻辑来保持角色与环境稳定,尽量避免帧与帧之间出现面部、服装或背景细节漂移。因此它更适合对角色一致性要求很高的专业叙事场景。
可以。它能够尽量保留产品细节,并复刻高端剪辑风格中的转场与摄像机移动,因此很适合用于制作更专业的营销内容、品牌广告和产品演示视频。
支持。你可以上传参考视频,再结合文本提示去修改风格、角色或场景,同时尽量保留原始动作和摄像机语言,因此它也适合做视频到视频类创作。
页面强调它建立在更强的物理理解能力之上,能够更好地处理重力、摩擦、流体和物体运动等真实世界动力学,因此像头发摆动、流水变化和物理交互会显得更有重量感和真实感。
双向扩展意味着你不仅能把现有片段向后延长,还能向前补足前情。这样更利于搭建完整叙事上下文,同时尽量保持环境、角色和镜头语言的连续性。
可以。你可以上传角色或产品的静态图像,再提供单独的视频参考,让模型学习其中的动作方式或镜头节奏,并把这些动态信息应用到静态主体上,同时尽量保留原始视觉细节。
Seedance 2.0 具备更强的剧本与故事板理解能力,能够解释结构化拍摄脚本或故事板图像,并理解镜头角度、灯光氛围与叙事推进逻辑,因此更适合生成遵循专业电影制作流程的多镜头序列。
如果你想把文本、图片、视频和音频参考整合进一个更专业的视频生成流程,并进一步控制一致性、动作表现与视频扩展,就从 Seedance 2.0 开始。